DART의 Open API를 이용해서 궁극적으로는 원하는 데이터를 콕 찝어서 가져와서 필요한 지표를 계산하는 그런 프로그램을 만들고 싶었습니다. 그런데 결론적으로는 지금 내 수준에서 단기적으로 달성하기에는 무리가 있는듯 하여 재무제표 조회의 수준에서 마무리하기로 했습니다. 이유는 뒷부분에서 얘기하겠습니다.
DART의 Open API 자체가 공시데이터의 목록 “조회만"을 목적으로 하고 있기 때문에 세부적인 Data의 조회는 편법을 이용해야 하며 그 편법을 위해서는 제 잔머리도 부족하고, 또 DART에서 자체적으로 세부Data를 일괄로 내려받을 수 있도록 해주고 있어서 굳이 새로운걸 만들어 쓸 필요가 없겠더라구요. 그래서 저는 이번 프로젝트는 이번 글에서 마무리하고자 합니다.
이번글은 DART에서 제무제표를 받아오는 프로그램을 만든 과정을 기록하고 있습니다. 이 프로그램은 데이터의 분석용과는 거리가 멀고 단순하게 Data를 조회하는 기능만 있습니다. 그리고 DART API에서 재무제표 데이터에 접근하기 위한 경로를 분석한 이전 글 DART API를 이용한 재무제표 접근법 에 기반하여 프로그램을 만들었습니다.
그럼 프로그램 만드는 과정 시작하겠습니다.
1.프로젝트 초기 세팅
1.1.프로젝트 생성
Visual Studio 2017에서 MFC 프로젝트를 생성합니다. 저는 일단 프로젝트 이름은 DartData로 정했습니다.
1.2.다이얼로그 구성
그리고 다음과 같이 Dialog를 구성했습니다.

1.2.1.구성요소
1. Edit Control: 종목코드 6자리를 입력받습니다.
2. Edit Control: 검색필터로 보고서 종류코드 bsn_tp를 입력받습니다.
3. Edit Control: 검색필터로 검색시작범위를 입력받습니다.
4. Edit Control: 검색필터로 검색종료범위를 입력받습니다.
5. Button Control: 1~4번의 검색 기본값을 바탕으로 DART에서 데이터를 불러오는 동작을 시작하는 트리거입니다.
6. Edit Control: 실행결과로 검색한 재무제표의 url을 표시합니다.
7. MFCGridCtrl: 실행결과로 재무제표의 데이터를 표시합니다.
2.필요한 라이브러리 추가
재무제표에 접근하기 위해서는 두가지 관문을 통과해야 하는데 그중 하나는 API를 통해 요청한 데이터가 xml로 반환되기 때문에 반환된 xml을 분석하는 것입니다. 그리고 나머지 하나는 html페이지에서 필요한 데이터들을 뽑아내야 하기 때문에 html코드를 분석하는것이 되겠습니다.
이렇게 xml과 html 파싱을 위해서 저는 인터넷으로 쉽게 구할 수 있는 파서를 선택해서 사용하였습니다.
2.1.xml parcer - Markup Release 11.5
Markup이라는 xml파서를 선택했습니다. xml파서도 다양한 솔루션들이 있지만 쉽게 찾을수 있었고 설명도 잘 되어 있어서 선택했던것 같습니다.
여기서 소스를 받아서 프로젝트에 추가했습니다.
2.2.html parcer - HTML Reader Class Library
xml과 html 모두 한번에 파싱해주는 라이브러리를 찾을 수 있었다면 좋았겠지만 그렇지 못해서 html 파서를 추가적으로 사용해야 했습니다. html 파서는 이전 글에서 언급한적이 있었는데요. CodeProject.com 에서 다운받은 예제를 활용한 것입니다.
여기에 웹접속에 대한 솔루션과 함께 파싱에 대한 예제도 잘 나와 있어서 선택을 했습니다. 저는 개인적으로 이 코드를 따라하면서 많은 공부가 되었던것 같습니다.
HTML Parcer 예제프로그램 분석과 코드 활용방안
마찬가지로 필요한 라이브러리파일들을 프로젝트에 모두 추가하였습니다.
2.3.Grid Control - MFCCridCtrl
조회된 데이터를 표로 출력해주기 위해서 grid control을 사용했습니다. 다양한 방법의 출력방법이 있겠지만 Grid Control사용법을 공부할 겸하여 사용해봤습니다. (grid control의 사용법은 다른 많은 분들의 블로그를 참고했습니다.)
3.코딩하기
3.1. Search 버튼을 눌렀을 때 동작하는 함수
아래 함수는 버튼을 눌렀을 때 호출되는 함수입니다. 이 프로그램은 버튼클릭 한번에 모든 루틴을 돌아서 결과를 출력해주기 때문에 이 함수의 내용에 프로그램의 모든 동작흐름이 모두 포함되어 있습니다.
소스에 대한 설명은 주석으로 대신하겠습니다.
void CDartDataDlg::OnBnClickedButSearch()
{
// #1 Dart 접속 초기 주소 초기화
edit_url = _T("http://dart.fss.or.kr/api/search.xml?auth=");
const CString auth_key = _T("f30033795dd53ee9788eb302cf4a93c4cdd41e77"); // DART에서 발급받은 인증키
edit_url += auth_key;
CString szUrlData;
GetDlgItemText(IDC_EDIT_crpcd, szUrlData);
edit_url += "&crp_cd=";
edit_url += szUrlData;
GetDlgItemText(IDC_EDIT_startdt, szUrlData);
edit_url += "&start_dt=";
edit_url += szUrlData;
GetDlgItemText(IDC_EDIT_enddt, szUrlData);
edit_url += "&end_dt=";
edit_url += szUrlData;
GetDlgItemText(IDC_EDIT_bsntp, szUrlData);
edit_url += "&bsn_tp=";
edit_url += szUrlData;
// #2 Url에서 소스data 받아오기
GetCodeFromUrl(edit_url);
// #3 소스data에서 사업보고서 접속주소 만들기
edit_url = ParseXml(m_szHtmlPage);
// #4 사업보고서 접속주소로 소스data 받아오기
GetCodeFromUrl(edit_url);
// #5 소스data에서 재무제표 접속주소 만들기
int position = m_szHtmlPage.Find(_T("연결재무제표\"")); // 첨엔 (_T("id: \"13\",")); 를 사용했었는데 정답이 아님
CString newHtml = m_szHtmlPage.Mid(position, 170); // 170: 그냥 충분한 길이
/// 기호를 기준으로 토크나이징
AfxExtractSubString(m_szRcpNo, newHtml, 1, '\'');
AfxExtractSubString(m_szDcmNo, newHtml, 3, '\'');
AfxExtractSubString(m_szEleId, newHtml, 5, '\'');
AfxExtractSubString(m_szOffset, newHtml, 7, '\'');
AfxExtractSubString(m_szLength, newHtml, 9, '\'');
AfxExtractSubString(m_szDtd, newHtml, 11, '\'');
/// 재무제표 주소 합성
edit_url.Format(_T("http://dart.fss.or.kr/report/viewer.do?rcpNo=%s&dcmNo=%s&eleId=%s&offset=%s&length=%s&dtd=%s"), m_szRcpNo, m_szDcmNo, m_szEleId, m_szOffset, m_szLength, m_szDtd);
UpdateData(0);
// #6 재무제표 url로 소스data 받아오기
GetCodeFromUrl(edit_url);
// #7 재무제표 소스를 파싱해서 원하는 데이터 가져오기
int i_maxcount;
if (!ParseHTML(m_szHtmlPage, i_maxcount)) // HTML코드 파싱
{
SetCell(1, 1, _T("연결회계 비대상 기업")); // 연결회계 비대상 기업
return;
}
// #8 가져온 데이터를 화면에 출력
SetCell(0, 1, m_age + m_unit); // 머릿글
int index = 0;
for (int i = 0; i < i_maxcount; i++) // 세부내역
{
if (mp_financial_dataset[i][0] != _T("") && mp_financial_dataset[i][1] != _T(""))
{
index++;
for (int j = 0; j < 2; j++)
{
SetCell(index, j, mp_financial_dataset[i][j]);
}
}
}
// 메모리 해제
for (int i = 0; i < i_maxcount; i++)
delete[] mp_financial_dataset[i];
delete[] mp_financial_dataset;
}3.2. 기본모듈
HTML, XML코드를 불러오고 불러온 코드를 문자열로 핸들링 하면서 필요한 인수를 찾아내는 루틴을 몇개의 함수로 모듈화 한 부분입니다.
그리고 Grid control의 각셀을 채워주는 함수도 간단하게 하나 넣었습니다.
// Dart API로 받은 XML 코드에서 rcpNo를 찾아내고
// 사업보고서에 접근할 수 있는 URL을 반환함
// 반환값: CString 사업보고서 URL
CString CDartDataDlg::ParseXml(LPCTSTR lpszString)
{
CMarkup xml;
ASSERT(lpszString != NULL);
if (xml.SetDoc(lpszString) == false)
return FALSE;
xml.ResetPos();
xml.FindChildElem(_T("list"));
xml.IntoElem();
xml.FindChildElem(_T("rpt_nm"));
xml.IntoElem();
m_age = xml.GetData(); // 현재 Element에서 값을 가져옵니다.
xml.FindElem(_T("rcp_no"));
m_szRcpNo = xml.GetData(); // 현재 Element에서 값을 가져옵니다.
CString szReportUrl = _T("http://dart.fss.or.kr/dsaf001/main.do?rcpNo=");
szReportUrl += m_szRcpNo;
return szReportUrl;
}
// LPCTSTR 타입으로 html소스를 전달받아 분석을 함.
// 소스분석결과 태그의 갯수가 100개 미만인경우는 재무제표가 이닌것으로 판단하여 FALSE 반환
// 파싱이 끝나면 TRUE를 반환하며 전체 태그 개수를 파라미터로 전달
bool CDartDataDlg::ParseHTML(LPCTSTR lpszString, int& iNoElements)
{
CLiteHTMLReader theReader;
CHtmlElementCollection theElementCollectionHandler;
theReader.setEventHandler(&theElementCollectionHandler);
CString szTag = _T("");
CString szAtrib = NULL;
CString szAtribVal = NULL;
theElementCollectionHandler.InitWantedTag(szTag, szAtrib, szAtribVal);//style
if (theReader.Read(m_szHtmlPage))
{
iNoElements = theElementCollectionHandler.GetNumElements();
// 연결 재무제표 페이지에서 tag요소가 100개 미만인경우는 연결회계 미적용 회사로 판단
if (iNoElements < 100)
return FALSE;
// 메모리 동적할당 부분 ==> 추후 vector로 수정예정
CString** p_temp = new CString*[iNoElements];
for (int i = 0; i < iNoElements; i++)
{
p_temp[i] = new CString[10];
}
mp_financial_dataset = p_temp;
HtmlTree hTree = theElementCollectionHandler.GetTree();
FillArray(hTree);
}
return TRUE;
}
// Url주소에서 반환되는 HTML,XML등 소스 data를 받아오는 함수
// 받아온 data는 멤버변수(m_szHtmlPage)에 저장
bool CDartDataDlg::GetCodeFromUrl(LPCTSTR lpszURL)
{
// #1 웹접속환경 초기화
CWebGrab Grab;
//set all params
Grab.SetTimeOut(2000);
//call init
Grab.Initialise(_T("Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) "), NULL);
// #2 Url에서 raw data 받아오기
CString sz_buff;
if (!Grab.GetFile(lpszURL, sz_buff, _T("Opera"), NULL))
return FALSE;
// #3 받아온 data를 변수에 저장
#ifdef _UNICODE
CString szPageW = UTF8Util::ConvertUTF8ToUTF16((char*)sz_buff.GetBuffer());
m_szHtmlPage = szPageW.GetBuffer();
#else
m_szHtmlPage = szBuff;
#endif
return TRUE;
}
// Grid Control의 cell 한칸을 채우는 함수
bool CDartDataDlg::SetCell(int iRow, int iCol, CString szText)
{
DWORD dwTextStyle = DT_RIGHT | DT_VCENTER | DT_SINGLELINE;
GV_ITEM Item;
Item.mask = GVIF_TEXT | GVIF_FORMAT;
Item.row = iRow;
Item.col = iCol;
Item.nFormat = dwTextStyle;
Item.strText.Format(_T("%s"), szText);
m_grid_datatable.SetItem(&Item);
m_grid_datatable.SetItemFgColour(iRow, iCol, RGB(255, 0, 0));
m_grid_datatable.Invalidate();
return false;
}3.3. HTML tag에서 필요한 Data 뽑아내기
지금까지의 코드는 누군가의 라이브러리를 이용하기 때문에 비교적 쉽게 접근했던 부분인데 머리아픈건 지금부터입니다.
제가 html코드의 parcer로 사용한 HTML Reader Class Library의 예제에서는 HTML코드를 tag구조 그대로를 트리형태의 자료주조로 만들어줍니다.
재무제표페이지에서 제가 가져와야 할 자료들은 테이블 형태로 만들어져 있어서 table tag에서 각 셀의 데이터는 트리구조의 leaf에 위치하게되는 특성이 있었습니다. 그래서 저는 트리 자료구조를 하나하나 순환을 하면서 leaf위치에 있는 데이터만 가져와서 포멧을 바탕으로 데이터를 구분시켰습니다.
글로 설명을 하기가 쉽지 않네요. 상세한 설명은 주석으로 대체하겠습니다. 이 글에 관심을 보이시는 분들이 좀더 계시다면 요청에 따라 부연설명을 추가해 보도록 하겠습니다.
static int giElements = 0; // 전체 요소의 수를 counting 하기위한 전역변수
static int g_cnt_tr_tag = 0; // tr태그 출현빈도를 카운팅하기위한 전역변수 (저장할 Data요소 수)
static int g_cnt_leaf_tag = 0; // 최하위 태그 출현빈도를 카운팅하기위한 전역변수 (tr태그출현시 reset)
void CDartDataDlg::FillArray(HtmlTree hTree)
{
giElements = 0;
InitDataTable();
g_cnt_tr_tag = 0;
g_cnt_leaf_tag = 0;
m_dwarrTagStart.RemoveAll();
m_dwarrTagLen.RemoveAll();
m_TableTagFlag = 0;
m_age = _T("");
m_unit = _T("");
LookAroundTag(hTree);
}
BOOL CDartDataDlg::LookAroundTag(HtmlNode node)
{
int iElements = node.Count; // 현재 노드에서 하위 노드의 객수를 확인
bool is_tr_tag = FALSE;
for (int n = 0; n < iElements; n++) {
// #1 flag 상태 업데이트
CString temp_tagname = node.Nodes[n]->szName;
if (temp_tagname.CompareNoCase(_T("tr")) == 0)
{
g_cnt_tr_tag++;
g_cnt_leaf_tag = 0;
is_tr_tag = TRUE; // tr 태그의 하위 leaf 개수를 저장
}
if (!node.Nodes[n]->iFiltered) {
giElements++;
}
if (!node.Nodes[n].IsLeaf()) // leaf가 아니면 재귀호출
{
LookAroundTag(node.Nodes[n]);
}
else // leaf에 도달한 경우
{
CString sz_tagname = node.Nodes[n]->szName;
LPCTSTR lp_pdata_startstop = node.Nodes[n]->lpszStartStop;
LPCTSTR lp_pdata_stopstart = node.Nodes[n]->lpszStopStart;
CString sz_data;
// 태그가 br이 아니이면서 6행 이상의 요소가 아닌 경우만 값을 추출
if (is_tr_tag && g_cnt_leaf_tag < 6 && (sz_tagname.CompareNoCase(_T("br")) != 0))
{
CString sz_temp(lp_pdata_startstop, lp_pdata_stopstart - lp_pdata_startstop);
sz_data = sz_temp;
}
// 혹은 태그가 br인경우만 값을 추출
else if (g_cnt_leaf_tag < 6 )
{
int stoppoint = _tcschr(lp_pdata_startstop, _T('<')) - lp_pdata_startstop;
CString sz_temp(lp_pdata_startstop, stoppoint);
sz_data = sz_temp;
}
// leaf개수가 6개 이상으로 넘어가면 불필요
else
{
return FALSE;
}
// 추출된 값을 한번더 필터링해서 설별적으로 구조화
sz_data.Replace(_T(" "), _T(""));
sz_data.Trim();
int i_type;
CString sz_temp = parceLeafValue(sz_data, i_type);
if (g_cnt_leaf_tag == 0) // 첫번째 항목명은 무조건 입력
mp_financial_dataset[g_cnt_tr_tag][g_cnt_leaf_tag] = sz_data;
else if(i_type == 1 && mp_financial_dataset[g_cnt_tr_tag][1] == _T("")) // 유의미한 숫자이고 1열이 비어있을 때 입력
mp_financial_dataset[g_cnt_tr_tag][1] = sz_temp;
g_cnt_leaf_tag++;
}
// tr 태그를 빠져나갈때
if (temp_tagname.CompareNoCase(_T("tr")) == 0)
{
is_tr_tag = FALSE; // tr 태그의 하위 leaf 개수를 저장
}
}
return FALSE;
}
// leaf tag data를 분석해서 해당 data의 종류를 구분하는 함수
// (CString)분석할문자열 => (CString)변환data (int)data종류
//----------------------------------------------------------
// >> 무의미값 (0): 빈칸이거나 자릿수 4개 이하
// >> "("로 시작했을 때,
// - 음수 (1): ")" 로 끝나는 경우
// - 단위 (0): "단위: " 가 검색될 경우
// >> 숫자로 시작했을 때,
// - 양수 (1): "," 개수 * 3 < 숫자 개수
// - 주석 (0): "," 개수 * 3 >= 숫자 개수
// >> 연도 (0): "제"로시작해서 "현재"로 끝나는 경우
// >> 항목명 (0): 그외
CString CDartDataDlg::parceLeafValue(CString sz_rawvalue, int& out_type)
{
LPTSTR psz_buffer = sz_rawvalue.GetBuffer(0);
TCHAR pch_buffer = psz_buffer[0];
// #1
if (4 > sz_rawvalue.GetLength())
{
// #1-1 빈칸인 경우
if (sz_rawvalue.IsEmpty())
{
out_type = 0;
return NULL;
}
// #1-2 "-" 만 있는 경우
else if (sz_rawvalue.Find('-') == 0 )
{
out_type = 1;
return _T("0");
}
out_type = 0;
return NULL;
}
// #2 "("로 시작하는 문자열일 때,
else if (psz_buffer[0] == _T('('))
{
// #2-1 "단위 :"라는 문자열이 포함된경우는 단위
if ((sz_rawvalue.Find(_T("단위")) != -1) && m_unit == _T(""))
{
out_type = 0;
m_unit = sz_rawvalue;
return NULL;
}
// #2-2 ")"로 끝나는 문자열일 때는 음수
else if (psz_buffer[_tcslen(psz_buffer) - 1] == _T(')') )
{
out_type = 1;
CString result(psz_buffer + 1, _tcslen(psz_buffer) - 2);
result.Replace(_T(","), _T("")); // ',' 기호를 삭제
return _T("-") + result;
}
}
// #3 ","로 분리된 숫자일때
else if (_ttoi(&pch_buffer) != 0)
{
int cnt_comma = 0;
int cnt_digit = 0;
int itt = _tcslen(psz_buffer);
for (int i = 0; i < itt; i++)
{
switch (psz_buffer[i])
{
case _T(','):
cnt_comma++;
break;
case _T(' '):
break;
default:
if (cnt_comma != 0)
cnt_digit++;
break;
}
}
// #3-1 "," 개수 * 3 < 숫자 개수 이면 양수
if (cnt_comma *3 <= cnt_digit)
{
out_type = 1;
sz_rawvalue.Replace(_T(","), _T("")); // ',' 기호를 삭제
return sz_rawvalue;
}
// #3-2 그렇지 않으면 무의미한 값
else
{
out_type = 0;
return NULL;
}
}
// #4
else
{
// #2-2 괄호도 아니면 구분제목인데 여기서 해당 년도를 가져올수 있음
int pos1 = sz_rawvalue.Find(_T("제"));
int pos2 = sz_rawvalue.Find(_T("현재"));
if ((pos1 == 0 && pos2 != -1) && m_age == _T(""))
{
m_age = sz_rawvalue.Right(17);
out_type = 0;
return NULL;;
}
}
out_type = 0;
return sz_rawvalue;
}4.결과

최종 결과로 이렇게 재무제표의 데이터를 확인해 볼 수 있었습니다. UI적인 부분에서는 부족한 부분이 많이 있지만 제 개인적인 입장에서 더 이상 개발의 필요성이 없기 때문에 이정도로 가능성만 확인하는 수준으로 마무리 했습니다.
그럼 글의 맨처음에서 언급했던, 제 수준에서의 더이상의 개발의 필요성을 느끼지 못하게 한 어려운점을 설명드리겠습니다.
원래 제가 목표한 결과를 얻기위해선 각 종목별, 연도별로 특정 지표를 일관되게 구별 해낼 수 있어야 합니다. 예를들어, 어떤 기간동안 매출이 가장 많이 증가한 (매출증가율이 높은) 기업 TOP10을 뽑고싶다면, 기업코드 목록을 순환하면서 당기 매출과 전기 매툴을 찾아서 변수에 넣고 증가율을 계산하고 기업코드 목록 순환을 마치면 결과값을 내림차순으로 정렬을 하면 되겠죠. 그런데 문제는 기업별 재무제표에서 매출이라는 항목을 딱 봅아내기가 쉽지 않습니다. 이유는 기업별로 매출이라는 항목을 표현하는 방식이 제각각이라는 겁니다.
아래는 DART에서 제공해주는 2017년 손익계산서 일괄 Data에서 매출이 어떤 이름으로 표현되는지 뽑아본것입니다. DART에서 제공해주는 자료를 보면 항목코드와 항목명이라는 분류가 있습니다. 항목코드는 DART내부적으로 DB관리를 위해서 부여된 코드인것 같고 항목명은 저희가 조회해서 보는 재무제표에 표시되는 문자인듯 합니다.
항목코드로로매출을 나타내는 "ifrs_revenue"만 골라서 보면 2017년도 한해만 봤는데도 이렇게 아래 6가지 용어로 사용되고 있는 걸 알수 있습니다.
매출액 / 수익(매출액) / 매출 / 영업수익 / 매출 및 지분법 손익 / I. 매출액
매출이라는 키워드로 검색을 하면 영업수익이라는 표현을 사용하는 기업은 결과값이 없을테고 그리고 더큰문제는 재무제표에는 매출이라는 단어가 들어가는 항목이 매출 말고도 더 있다는 거죠. (매출원가, 공사매출, 매출총이익, 차감매출 등)
API에서 항목코서를 직접 조회 할 수 있다면 좋겠지만 그렇지 않기 때문에 항목명을 가지고 매출에 해당하는 데이터를 찾을 수 밖에 없는데, 검색결과가 상호베타적이면서 전체포괄적인 상황을 보장해 주지 못하기 때문에 여기서 또 꼽수적 기법이 필요합니다. 이것이 바로 저의 귀차니즘이 발동한 부분이었습니다. ㅎ
하지만 다행이도 DART에서는 다운받을 수 있는 일괄 재무데이터를 제공해주고 있으니. 그냥 이거 가져다 쓰고 괜히 잔머리 굴릴 필요없겠다라고 결론을 내렸습니다. 아래 재무데이터 일괄다운로드 받는 위치 참고하시고 전 포스팅 마치도록 하겠습니다.
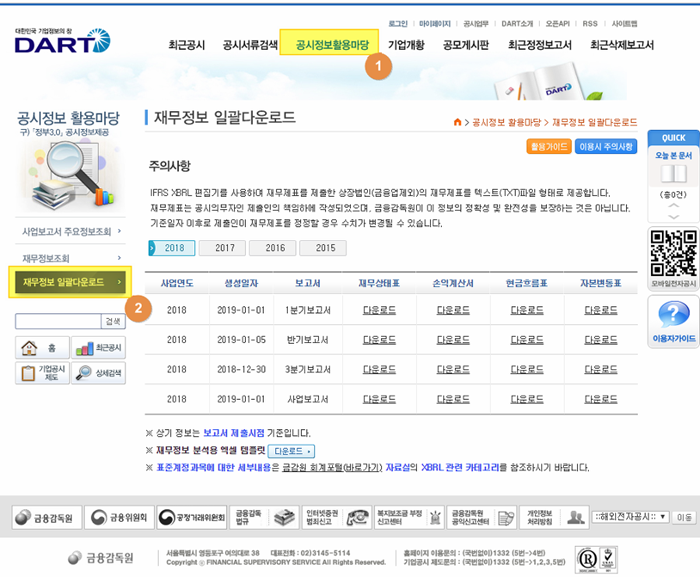
끝!
'Software > HTS만들기' 카테고리의 다른 글
| DART API를 이용한 재무제표 접근법 (2) | 2018.12.03 |
|---|---|
| 전자공시시스템(DART) API 신청하기 (0) | 2018.10.25 |


댓글