2023-04-05 update log: 공공데이터 포털 API주소 변경 및 Qt함수 변경으로 인한 에러 수정
공공데이터 포탈의 OpenAPI를 이용해서 조달청 공고 입찰 정보를 조회하는 프로그램 만들기 2부입니다. 지난 포스팅에서는 API에서 제공하는 정보의 구성과 내용에 대해서 확인해 봤었는데요.
조달청 입찰/계약 정보 조회용 프로그램 (1/ 2) - 공공데이터포탈 API 분석 및 GUI구성
조달청에서 제공하는 API를 이용해서 정부 발주 입찰공고 및 계약현황을 조회하는 파이썬 프로그램을 만들어 보려 합니다. 국가종합 전자조달 홈페이지인 나라장터에서 필요한 정보 조회가 모
kwonkyo.tistory.com
이번에는 분석 내용을 바탕으로 파이썬 코딩 진행해 보겠습니다. 여기서는 제가 공부하면서 어려웠던 부분들 그리고 알아두면 나중에도 유용하게 사용할 수 있는 부분들 위주로만 설명을 하겠습니다. 대신 계획한 기능을 모두 구현한 전체 버전의 코드는 본 포스팅 가장 마지막 부분에 첨부하였으니 필요하신 분은 참고하세요.
먼저 필요한 라이브러리를 로딩합니다. 파일 시스템 접근, 시간 계산, 실수 계산, json 사용 등에 필요한 라이브러리들 추가합니다. 그리고 DB 사용을 위해서 sqlite3와 panadas도 추가했습니다. 그리고 API로 불러온 xml포맷의 데이터를 파싱하기 위해서 beutyfulsoup도 추가했습니다.
마지막으로 "WaitingSpinnerwidget"이라는 커스텀 라이브러리 추가했는데요. 서버 데이터를 요청해서부터 자료를 받아와서 화면에 표시하기까지 대기해야 하는 시간 동안 프로그램이 동작중이라는 걸 표현하기 위해서 로딩 화면을 그려주는 기능을 합니다.
코드 구성
import os
import time
import math
import json
import sqlite3 # DBMS 임포트
import pandas
import webbrowser
from urllib import parse, request
from pandas import DataFrame
from bs4 import BeautifulSoup
from PyQt5.QtWidgets import *
from PyQt5 import uic, QtGui
from PyQt5.QtCore import *
from WaitingSpinnerWidget import Overlay # 로딩 스피너
import apikey프로그램이 동작하면서 전반적으로 사용되는 전역 변수를 설정합니다.
BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # python실행 경로
## 고정값 설정
DB_FILE = "G2BDB.db" # DB 파일명 지정
API_KEY = apikey.mykey
API_URL = "http://apis.data.go.kr/1230000/BidPublicInfoService04"
OPT_NAME_BIDC = "/getBidPblancListInfoCnstwkPPSSrch01?" #입찰공고 공사조회
## 검색중인URL 저장용 전역변수
url_pre = ""
url_sub = ""
Ui_MainWindow = uic.loadUiType(BASE_DIR+r'\G2BDataAPI.ui')[0]
global start_time #데이터 다운로드 시간 계산용 전역변수
start_time = 0.0BASE_DIR은 실행되는 파이썬 코드가 위치한 경로를 저장하는 변수입니다. PyQt UI파일과 SQLite 파일을 불러오는 데 사용합니다.
API_KEY는 공공데이터 포털에서 신청한 API 상세 정보 페이지에서 확인할 수 있는 인증키로 정의합니다. (2023-4-5 수정) "apikey.py"라는 별도 파일에 "mykey"라는 변수로 인증키를 정의하고 불러와서 사용하도록 했습니다. 그리고 API를 요청하는 End Point 주소는 API_URL로 정의하였습니다. (API 요청 주소도 변경되었습니다)
입찰공고 조회용 API에는 다양한 오퍼레이션이 있는데요. 그중에서 원하는 오퍼레이션명을 찾아야 하는데요. API 참고 문서에서 찾을 수 있습니다. 여기서는 "나라장터검색조건에 의한 입찰공고 공사조회"라는 오퍼레이션이 필요하기 때문에 해당 오퍼레이션명은 OPT_NAME_BIDC 변수로 정의하였습니다. (오퍼레이션 주소도 변경되었습니다)
그 외 PyQt UI도 지정하고 검색에 걸리는 시간을 계산하기 위한 용도의 전역 변수 start_time도 하나 만들었습니다.
다음으로 조회한 데이터를 저장하는 DB를 초기화하는 루틴입니다. 위에서 정의했던 BASE_DIR 위치에 DB_FILE 변수에 정의된 파일 이름의 DB파일이 있다면 해당 DB에 연결하고 그렇지 않다면 새로운 DB파일을 생성합니다.
## DB파일이 없으면 새로 만들고
if os.path.isfile(BASE_DIR + "//" + DB_FILE):
con = sqlite3.connect(BASE_DIR + "//" + DB_FILE)
cursor = con.cursor()
else:
con = sqlite3.connect(BASE_DIR + "//" + DB_FILE)
cursor = con.cursor()
cursor.execute("CREATE TABLE bid_list(bidno text PRIMARY KEY, bidissue date, bidname text, client text, price text, url text)")DB 테이블은 입찰공고번호, 날짜, 공고명, 수요기관, 금액, 공고문주소로 6개 data를 저장하도록 구성하였습니다. 날짜 칼럼만 "date"형식을 사용하고 나머지는 모두 "text"형식으로 지정했습니다. 그리고 맨 마지막에 있는 url(공고문 주소) 칼럼은 화면에는 보여주지 않지만 해당 공고를 더블클릭했을 때 공고문을 웹브라우저로 열기 위해서 사용할 예정입니다.
지금부터는 클래스를 얘기할 차례인데요. 저는 프로그램 메인 스트림을 담당하는 "MyDialog" 클래스와 API를 통한 데이터 크롤링을 담당할 "CrawlRunnable" 클래스로 구성하였습니다.
아래는 MyDialog 클래스입니다.
class MyDialog(QMainWindow, Ui_MainWindow):
######### 중 략 #########
# 메인테이블에 DB 데이터 표시하기
def refreshMainTable(self):
con = sqlite3.connect(BASE_DIR + "//" + DB_FILE)
cursor = con.cursor()
cursor.execute("SELECT * FROM bid_list")
table = self.tableWidget
table.setRowCount(0)
for row, form in enumerate(cursor):
table.insertRow(row)
for column, item in enumerate(form):
if (column<5):
table.setItem(row, column, QTableWidgetItem(str(item)))
self.arrangecolumn()
con.close()
# 메인테이블 초기화
def initMainTable(self):
table = self.tableWidget
table.setColumnCount(5)
table.setRowCount(0)
table.setHorizontalHeaderLabels(["번호","공고/계약일","사업명","기관명","금액"])
self.refreshMainTable()
# 입찰공고를 검색하기
def btn_search(self):
global start_time
start_time = time.time() # 시작시간 리셋
self.overlay.setVisible(True) # 스피너 시작
## 검색페이지 요청
table = self.tableWidget
table.clearContents()
runnable = CrawlRunnable(self)
QThreadPool.globalInstance().start(runnable)
# 키워드목록에서 더블클릭이 발생하면 해당 항목의 공고문을 웹브라우저로 호출
def cell_DBclicked(self, row, col):
sel_key = self.tableWidget.item(row,0)
sel_key = sel_key.text()
print(sel_key)
con = sqlite3.connect(BASE_DIR + "//" + DB_FILE)
cursor = con.cursor()
cursor.execute("SELECT * FROM bid_list WHERE bidno=?", (sel_key, ))
sel_key = cursor.fetchone()
con.close()
if (sel_key):
sel_key = sel_key[5]
webbrowser.open(sel_key)
######### 중 략 #########
@pyqtSlot()
def search_finish(self):
self.refreshMainTable()
self.overlay.setVisible(False)
## 실행시간 표시
global start_time
end_time = time.time() ##계산완료시간
time_consume = end_time - start_time
time_consume = '%0.2f' % time_consume ##소수점2째자리이하는 버림
self.lineEdit_time.setText(str(time_consume) + "초 소요")MyDialog 클래스는 프로그램이 시작했을 때 화면 구성 등 초기화 관련 기능을 우선 수행하게 됩니다. 그리고 UI의 각 부분의 액션 피드백을 담당하는 함수들이 포함되어 있는데 그중에서 핵심 루틴의 시작이 되는 "DB다운로드" 버튼은 함수 "btn_search"와 연결되어 있습니다.

btn_search() 함수가 호출되면 타이머에 사용될 변수인 start_time에 현재시간을 저장하고 데이터 다운로드 중 인 것을 알 수 있도록 로딩 화면(스피너)을 보여주는 레이어를 활성화합니다. 다음으로 CrawlRunnable이라는 클래스를 실행할 새로운 스레드로 등록하고 스레드를 실행합니다.
크롤링 작업을 별도의 스레드를 사용하는 멀티 스레드 처리를 한 이유는 데이터를 받아오는데 생각보다 많은 시간이 소요되어서 작업 동안에 마치 프로그램이 다운된 것 같은 모양이 되었습니다. 그래서 데이터를 받는 루틴을 백그라운드에서 처리하도록 하였습니다.
아래 코드는 백그라운드에서 처리되는 CrawlRunnable 클래스입니다.
## 데이터 크롤링을 담당할 쓰레드
class CrawlRunnable(QRunnable):
def __init__(self, dialog):
QRunnable.__init__(self)
self.w = dialog
# 크롤링 루틴
def crawl(self):
date_start = self.w.dateEdit_start.date().toString("yyyyMMdd")
date_end = self.w.dateEdit_end.date().toString("yyyyMMdd")
page_no = self.w.lineEdit_curPage.text() #페이지
dminsttNm = self.w.lineEdit_dminsttNm.text() #수요기관
presmptPrceBgn = int(self.w.lineEdit_minVal.text())*100000000 #추정가격
bidNtceNm = self.w.lineEdit.text() #공고명
start = parse.quote(str(date_start)) #검색기간 시작일
end = parse.quote(str(date_end)) #검색기간 종료일
keyword = parse.quote(self.w.lineEdit.text()) #공고명 검색 키워드
numOfRows = parse.quote(str(40)) #페이지당 표시할 공고 수
page = parse.quote(str(page_no)) #다운로드할 페이지 번호
if self.w.radioButton_bidC.isChecked(): # "입찰공고 공사" 선택 시
url = (API_URL + OPT_NAME_BIDC
+ "inqryDiv=1&"
+ "inqryBgnDt="+start+"0000&"
+ "inqryEndDt="+end+"2359&"
+ "numOfRows="+numOfRows+"&"
+ "ServiceKey="+API_KEY+"&"
+ "pageNo="+ page_no
)
if dminsttNm != "": # 수요기관 검색조건이 있으면 추가
url = url+"&"+"dminsttNm="+parse.quote(dminsttNm)
if presmptPrceBgn != 0:
url = url+"&"+"presmptPrceBgn="+parse.quote(str(presmptPrceBgn)) # 추정가격 검색조건이 있으면 추가
if bidNtceNm != "":
url = url+"&"+"bidNtceNm="+parse.quote(bidNtceNm) # 공고명 검색조건이 있으면 추가
## 그 외 공고 검색 루틴은 생략
else:
pass
req = request.Request(url)
resp = request.urlopen(req)
rescode = resp.getcode()
if(rescode==200):
response_body = resp.read()
html=response_body.decode('utf-8')
soup = BeautifulSoup(html, 'lxml')
## BeautifulSoup에서 아이템 검색시 모두 소문자로 검색해야 함
totalCount = soup.find('totalcount') #검색조건에 해당하는 전체 공고수
pageNo = soup.find('pageno') #요청한 페이지 번호
totalPageNo = math.ceil(int(totalCount.string) / int(numOfRows)) #전체 페이지 수
self.w.label_3.setText(str(totalPageNo)+"페이지("+totalCount.string+"건)중 페이지")
self.w.lineEdit_curPage.setText(pageNo.string)
## 크롤링 쓰레드에서 처리할 DB연결
con = sqlite3.connect(BASE_DIR + "//" + DB_FILE)
cursor = con.cursor()
for itemElement in soup.find_all('item'):
#조회 데이터를 DB에 입력
if self.w.radioButton_bidC.isChecked():
price = itemElement.presmptprce.string
if price == None:
price = "0"
price = format(int(price),',')
cursor.execute("INSERT or IGNORE INTO bid_list VALUES(?,?,?,?,?,?);",
(itemElement.bidntceno.string, # 공고번호
itemElement.bidntcedt.string, # 공고일시
itemElement.bidntcenm.string, # 공고명
itemElement.dminsttnm.string, # 발주처
price, # 가격
itemElement.bidntcedtlurl.string)) # 공고문주소
## 그 외 공고 검색 루틴은 생략
else:
pass
con.commit() # 작업내용을 테이블에 수행
con.close()
else:
print("Error Code:" + rescode)
def run(self):
self.crawl()
QMetaObject.invokeMethod(self.w, "search_finish",
Qt.QueuedConnection)CrawlRunnable 클래스는 QRunnable을 상속받고 있는데 이 클래스는 실행되면 자동으로 내부에 run() 함수를 호출하게 되어 있습니다. run() 함수는 crawl()이라는 함수를 호출하고 crawl() 함수의 작업이 완료되었을 때 "search_finish"라는 이름의 함수가 호출되도록 예약합니다.
crawl() 함수는 전역 변수로 정의된 End Point 주소와 API 키 등을 조합해서 API 호출 URL을 생성합니다. 이 URL 뒤쪽으로는 다양한 검색조건을 첨부하여 완성되는데 이런 방식의 서비스를 REST GET 방식이라고 하는데 URL의 구성은 다음과 같습니다.
http://[API_URL]/[OPT_NAME]?serviceKey=[API_KEY]&[요청변수1]=[요청Data1]&[요청변수2]=[요청Data2]&...
각 위치에 해당되는 값으로 치환을 하면 아래와 같은 형태의 호출 주소가 되겠죠.
http://apis.data.go.kr/1230000/BidPublicInfoService04/getBidPblancListInfoCnstwkPPSSrch01?
serviceKey=ZgOrVh.....&numOfRows=10&pageNo=1&inqryDiv=1&inqryBgnDt=202102010000&inqryEndDt=202103052359&...
"?"를 기준으로 앞에는 호출 주소를 뒤에는 검색조건이 위치하고 있습니다. 그리고 각 검색조건들은 "&"로 연결될 수 있으며 검색 변수와 데이터는 "="로 묶인 쌍으로 되어있습니다. 각 검색 조건에 대한 데이터 포맷은 공식 참고 문서에 자세히 설명되어 있습니다.
이렇게 만들어진 URL을 이용해서 44~45행에서 "request"라이브러리를 이용해서 서버에 요청 메시지를 보내게 됩니다.
요청한 메시지에 의해서 정상적인 서버 응답이 도착하게 되면 접수한 xml 포맷의 데이터는 beutifulsoup 라이브러리가 파싱 하고, 찾아낸 데이터는 72행에서 즉시 SQLite DB에 저장하도록 하였습니다.
여기까지 크롤링을 수행한 백그라운드 스레드가 종료되면 바로 다음 호출이 예약이 되어있는 search_finish() 함수로 넘어가는데 이 함수는 위에서 살펴본 MyDialog클래스 안에 정의되어 있습니다. search_finish() 함수는 스피너를 표시하는 레이어를 종료하고 start_time변수에 저장된 시간으로부터 지금까지 소요된 시간을 계산하며 refreshMainTable() 함수를 호출해서 DB에 저장된 Data를 "tableWidget"에 뿌려줍니다.
실행화면

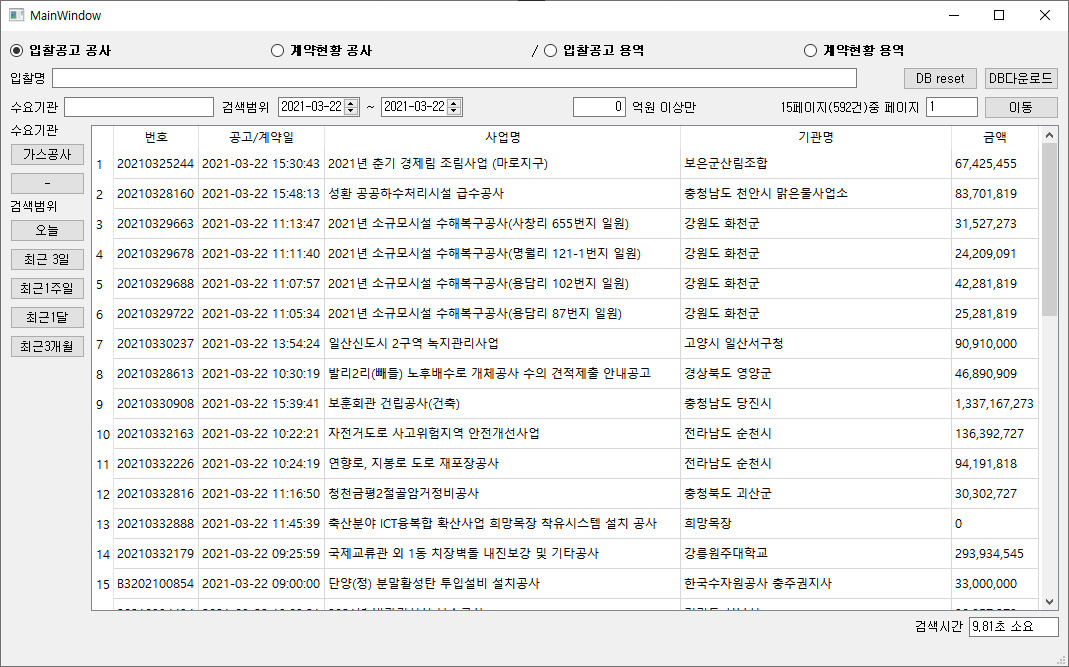
마무리
다양하게 잘 만들어진 라이브러리들과 방대한 레퍼런스 덕에 파이썬을 잘 모르지만 이 정도는 만들어 볼 수 있게 되었습니다. 아직 활용할 만한 수준에는 못 미치기 때문에 공부해서 개선할 부분들은 많이 남아 있습니다. 가장 취약한 부분이, 데이터를 받아와서 파싱 하고 DB에 저장하는데 걸리는 시간이 너무 오래 걸리고 있습니다. 검색 결과가 30개 정도 되는 데이터 기준으로 자료 요청에서부터 화면에 보여주기까지 약 5초 정도 시간이 소요되는데 조달청 사이트에서 직접 검색하는 것과 비교했을 때 너무 오래 걸리고 있습니다. 데이터 처리를 최적화하는 방법에 대해서 공부가 시급한 것 같습니다. 그 외에도 오류나 비정규 데이터 처리 그리고 화면에 표시되는 데이터의 시인성에도 개선이 많이 필요하고... 앞으로 갈길이 머네요.
끝!
PS. 프로그램 전체 버전
GitHub - lovey25/G2BDataAPI
Contribute to lovey25/G2BDataAPI development by creating an account on GitHub.
github.com
'Software > Python' 카테고리의 다른 글
| 로그인 후 리디렉팅하는 사이트 크롤링 (0) | 2021.05.17 |
|---|---|
| VSCode Python Extension에서 멀티 스레드 디버깅 (0) | 2021.03.23 |
| 조달청 입찰/계약 정보 조회용 프로그램 (1/ 2) - 공공데이터포탈 API 분석 및 GUI구성 (13) | 2021.03.19 |
| PyQt5 오버레이 레이어 Ver.2 (3) | 2020.12.03 |




댓글