파이썬에서는 크롤링을 아주 쉽게 할 수 있습니다. 파이썬을 모른다고 하더라도 예제 코드만 있으면 손쉽게 원하는 크롤링을 해볼 수 있을 정도로 간단한데, 오늘은 간단하게 시작했다가 몇 번의 시행착오를 격고서야 성공할 수 있었던 크롤링 작업에 대한 로그입니다.
로그인을 해서 권한을 얻은 후에 접근할 수 있는 페이지를 크롤링해야 할 일이 생겼고, 관련 예제는 인터넷에서 쉽게 찾을 수 있었습니다.
import requests
from bs4 import BeautifulSoup
login_url = '로그인페이지주소/login.aspx'
crawl_url = '크롤링할주소\Status.aspx'
login_info = {
'UserID': '아이디',
'UserPW': '비밀번호'
}
with requests.Session() as ss:
req = ss.post(login_url, data=login_info, verify=False)
if(req.status_code == 200):
soup = BeautifulSoup(req.content, 'html.parser')
_FORM = soup.select('p')코드는 아주 심플합니다. 먼저 인터넷으로 정보를 주고받기 위해서 "requests"라는 라이브러리와 받아온 HTML 페이지를 쉽게 파싱 하기 위해서 "BeautifulSoup"이라는 라이브러리를 사용합니다.
어떤 정보에 접근하기 위해서는 해당 정보가 있는 웹사이트 주소와 그 주소에 접근하는데 필요한 인증정보 등이 필요한데요. 여기서는 로그인을 처리하는 페이지의 주소인 login_url과 정보가 있는 위치의 주소인 crawl_url을 사용합니다. 그리고 웹사이트에 로그인하는데 필요한 아이디 패스워드를 login_info라는 변수에 사전 형태로 저장하였습니다.
12행에서 requests라이브러리에 있는 Session() 함수를 사용해서 세션을 생성하고 세션 안에서 필요한 동작을 수행할 수 있도록 with 구문으로 묶어져 있습니다. with 블록을 빠져나오면 세션이 끝나기 때문에 관리가 편리하다고 하네요.
13행은 실제로 인터넷 상의 서버와 직접 통신을 시작하는 가장 중요한 부분입니다. 인터넷에서 서버에 정보를 요청하는 방법은 대표적으로 "GET"과 "POST" 두 가지 방법이 있는데요. GET 방법은 간단히 말해서 웹브라우저의 주소창에 주소를 입력하는 방법입니다.


브라우저의 개발자 도구를 열어놓은 상태에서 주소창에 이동하려는 사이트의 URL을 입력하고 엔터를 누르면 브라우저는 어딘가로 메시지를 발송하는데 이 메시지의 헤더를 보면 위 사진처럼 URL을 "GET"이라는 방법으로 전송했다는 걸 알 수 있습니다. URL 문자열로만 통신을 할 수 있는 방법이라서 간단하긴 하지만 문자열이 그대로 노출되며 전송되는 데이터의 양에 제약이 있다는 단점이 있습니다.
반면 POST는 정보를 메시지 내부에 싸서 전송하는 방식입니다. GET이 엽서라면 POST는 편지라고 비교할 수 있을 것 같습니다. POST는 데이터 전송 기반으로 한 방법이기 때문에 보낼 정보의 양에 제약이 없고 전달되는 데이터가 겉으로 보이지 않습니다.
아래 그림처럼 네이버에서 로그인을 한다고 할 때 아이디와 주소를 적고 로그인 버튼을 눌러서 '로그인시켜주세요'라는 메시지를 보내는 방식에서 사용합니다. 이때 브라우저의 개발자 도구로 요청되는 데이터를 확인해보면 POST 방식으로 간다는 걸 알 수 있습니다.


13행의 함수를 얘기하려고 많이 돌아왔는데 post()라는 함수가 바로 POST 방식으로 정보를 요청하는 역할을 합니다. 파라미터로는 3가지가 사용되었는데요.
login_url: 데이터를 보낼 목적지의 주소입니다.
data: 목적지로 보낼 정보들입니다.
verify: False옵션을 사용할 경우 SSL 관련 에러를 무시할 수 있습니다.
(그리고 여기서는 사용하지 않았지만 allow_redirects 옵션을 추가하면 리디렉션 페이지인 경우 리디렉션을 막을 수 있습니다.)
만약 요청한 정보대로 서버에서 정상적인 응답을 했다면 서버에서 보내준 정보들이 "req"라는 변수에 저장되고 15행으로 동작이 이어집니다.
15행에서는 req변수에서 contents라고 하는 구조에 저장된 소스코드, 그러니까 웹브라우저라면 화면에 보이는 HTML 코드를 "html.parser"라고 하는 내장 파서를 이용해서 분석하게 됩니다. 그리고 분석한 내용은 soup이라는 변수에 저장합니다.
여기까지가 크롤링을 위한 기본 동작입니다. 이제 soup변수에 저장된 정보에서 필요한 부분을 꺼내 쓰기만 하면 됩니다. 여기서 16행에서는 HTML <p> 태그가 사용된 모든 내용을 찾아서 _FORM 변수에 리스트 형태로 저장하게 됩니다.
그런데 위에 설명된 기본적인 로그인 샘플 코드는 아주 기본적이고 필수적인 부분만 다루고 있기 때문에 안전을 이유로 다양한 보안 기법이 적용된 실제 서버들에서는 적용하지 못하는 경우가 많습니다. 제가 이번에 경험한 경우도 단순히 로그인만 했다고 세션이 로그인 상태로 유지되지 못했고 정보가 있는 페이지까지 접근하지 못했습니다.
위의 코드 14행에서 분명히 status_code 200이 응답되는 걸 확인했지만 그 이후 페이지로 이동할 때마다 계속 로그인 페이지로 돌아가는 현상이 나타났습니다. 그래서 브라우저의 개발자 도구로 캡처한 로그인 과정을 다시 한번 유심히 살펴봤습니다. (제가 크롤링하고자 하는 서버에 악영향이 있을지 몰라서 해당 서버를 특정하지 않는 점 양해해 주세요.)

사이트의 유효한 인증을 확인하는 흐름은 위 그림과 같은 것 같습니다. 최초 로그인 시에는 아이디와 비밀번호만으로 인증을 하고 인증에 성공하면 로그인된 화면으로 이동합니다. 그런데 여기서 특정 페이지의 정보를 요청하면 아이디와 비밀번호 이외에도 추가적인 정보가 필요한 것 같았습니다.
아래는 로그인 버튼을 누르고 나서부터의 통신내용입니다. 로그인에 성공했을 때 먼저 어떤 페이지가 먼저 응답을 하고(왼쪽) 로그인 후 인증정보를 가지고 최종 목적 페이지로(오른쪽) 이동합니다.

그리고 첫 번째에서 두 번째 페이지로 자동 리디렉팅 할 때 쿠키 정보가 같이 넘어가는 걸 볼 수 있었습니다.

그런데 문제는 이 쿠키 정보를 받아서 넘기는걸 몇 번 시도해 봤는데 쉽사리 성공하지 못했고 다른 편법으로 성공할 수 있었습니다.
이 서버만의 특징인지 모르겠지만 GET 방식으로 로그인 후 목적 페이지로 리디렉팅 하는 접근이 가능했습니다. 아래처럼 URL 마지막에 "?reurl="이라는 키워드로 로그인에 성공했을 때 이동할 페이지를 미리 서버에 요청할 수 있었고 이때 서버에 전달되는 Form Data를 확인할 수 있었습니다.

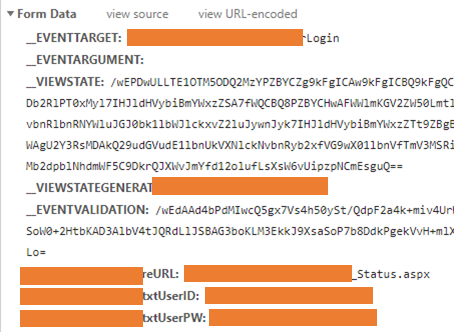
여기에서 필요한 Form Data들은 다행히 모두 로그인 페이지에서 확인이 가능한 것들이어서 소스코드를 다음과 같이 수정해서 원하는 페이지로 접근할 수 있었습니다.
with requests.Session() as ss:
req = ss.post(login_url, data=login_info, varify=False)
if(req.status_code == 200):
soup = BeautifulSoup(req.content, 'html.parser')
_FORM = soup.select('html > body > form > input')
params = {
'__EVENTTARGET': 'MemberLogin',
'__EVENTARGUMENT': '',
_FORM[0]['name'] : _FORM[0]['value'],
_FORM[1]['name'] : _FORM[1]['value'],
_FORM[2]['name'] : _FORM[2]['value'],
'Main$reURL': '/Status.aspx',
'UserID': '아이디',
'UserPW': '비밀번호'
}
res_status = ss.post(crawl_url, data=params)
if(res_status.status_code == 200):
soup = BeautifulSoup(res_status.text, 'html.parser')5행에서 페이지 이동에 필요한 인증정보가 담겨있는 <input> 태그들만 긁어서 _FORM 변수에 저장합니다.
6행에서는 _FORM 변수에서 서버로 넘겨질 데이터를 추출해서 params라는 이름의 사전 변수를 만들어 줍니다.
이렇게 준비된 파라미터는 17행에서 다시 한번 서버로 요청을 날리게 되는데 여기서 목적지 URL은 크롤링을 할 주소가 저장된 crawl_url을 사용했습니다.
아마도 사용자 인증을 유효화 하는 데는 쿠키 정보를 바탕으로 서버와 통신을 이어가는 게 정상적인 방법인 것 같은데 일단 급한 대로 이런 편법도 가능하기에 기록으로 남깁니다.
끝!
'Software > Python' 카테고리의 다른 글
| 파이썬에서 날짜 관련 요긴한 정보 - datetime (0) | 2021.06.12 |
|---|---|
| 파이썬으로 라인 메신저에 알림(메시지) 보내기 - Python to LINE Notify (4) | 2021.06.05 |
| VSCode Python Extension에서 멀티 스레드 디버깅 (0) | 2021.03.23 |
| 조달청 입찰/계약 정보 조회용 프로그램(2/2) - 코딩 (27) | 2021.03.22 |



댓글