네이버 쇼핑의 검색 결과가 필요해졌습니다. 검색 페이지 크롤링하면 되니까 어렵지 않게 할 수 있을 거라고 생각했었는데 그게 아니었습니다. 대신 검색정보를 담고 있는 JSON파일을 찾을 수 있었고 더 쉬운 방법으로 해결이 되어서 내용을 남깁니다.
크롤링의 기본은 사이트의 구조를 파악하는 일이죠. 저는 특정 카테고리의 해외직구 제품 네이버 랭킹 1~100위 제품을 가져올 계획이고 여기서 그 카테고리는 TV입니다.
먼저 해당 페이지를 분석해보겠습니다. "네이버 > 쇼핑 > 카테고리TV > 해외직구"로 이동합니다.
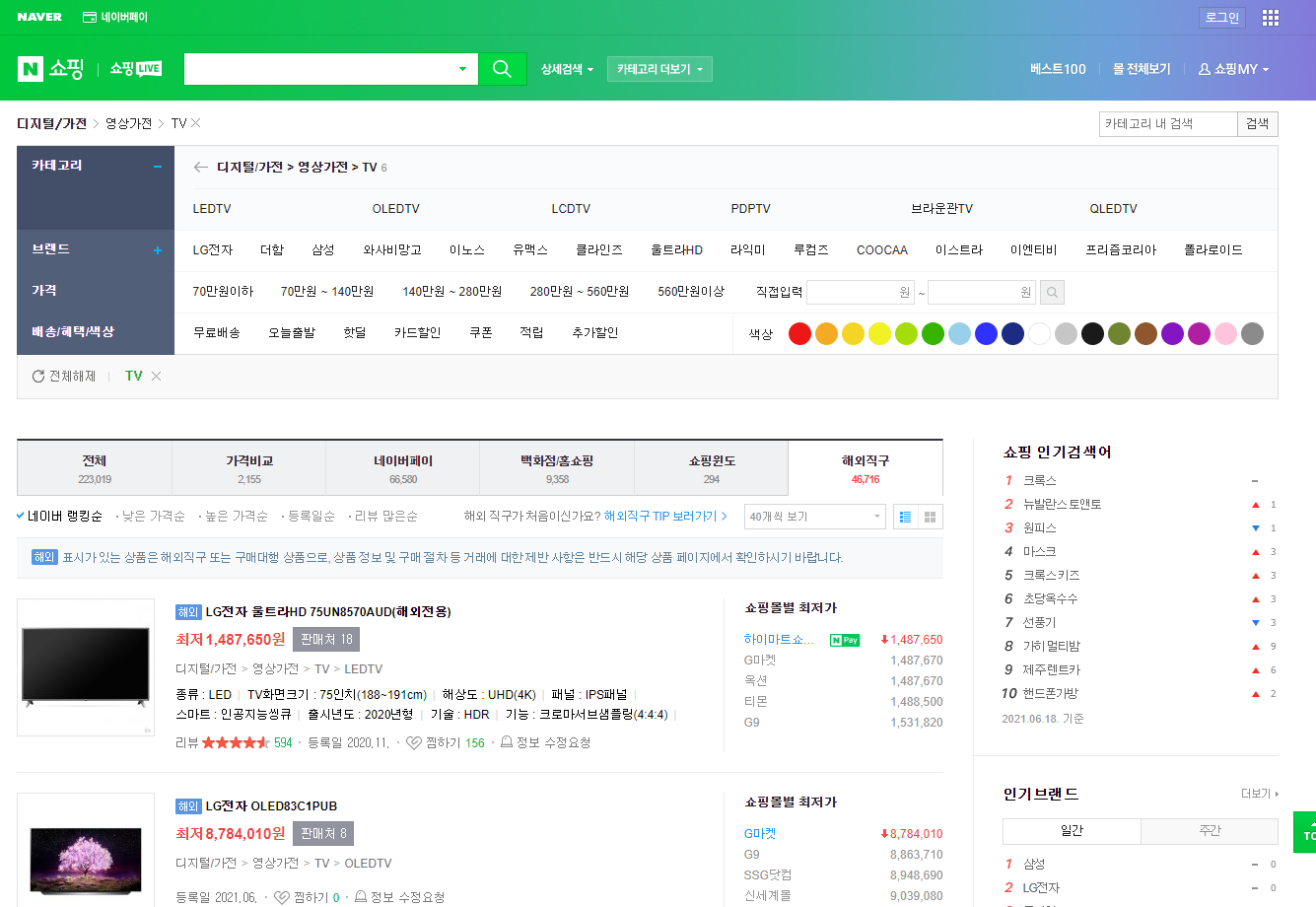
F12 or Ctrl+Shift+I 를 눌러서 "개발자 도구"를 열어줍니다. 여기서는 로딩되는 웹페이지의 모든 정보를 볼 수 있습니다.

그리고 좌측 상단의 마우스 모양의 버튼 or Ctrl+Shift+C를 눌러서 요소 선택을 활성화합니다. 그런 다음 마우스를 네이버 쇼핑으로 이동시켜서 이리저리 움직여보면 화면에 표시된 요소들이 하이라이트 되면서 각 요소의 경계가 표시됩니다.
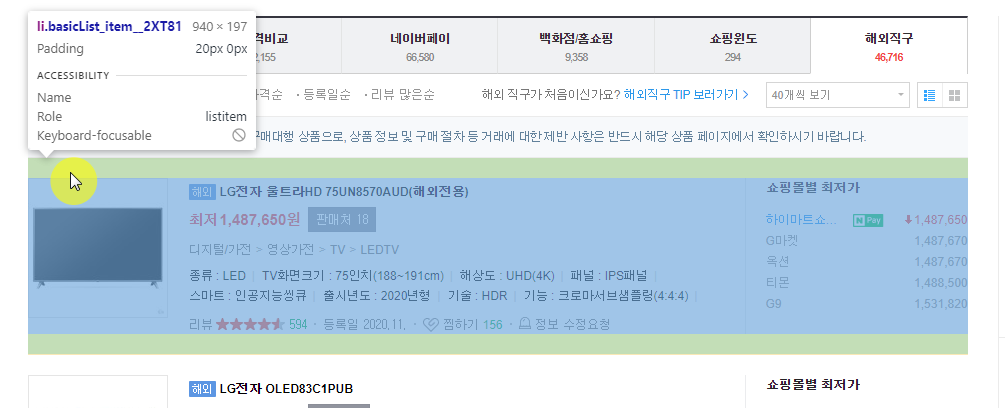
잘 움직이다가 검색 결과 중 한 개의 아이템 영역을 모두 커버하는 위치를 찾았을 때 클릭을 해줍니다. 그러면 개발자 도구에서 해당 요소에 해당하는 HTML 코드가 있는 위치로 이동하게 됩니다.

화면에 나타나는 제품명, 가격, 등록일 등등 다양한 정보들을 찾을 수 있습니다. 브라우저의 주소창을 보면 검색 결과가 보이고 있는 현 페이지의 주소가 다음과 같다는 걸 알 수 있습니다.
https://search.shopping.naver.com/search/category?catId=50001395&frm=NVSHOVS&origQuery&pagingIndex=1&pagingSize=40&productSet=overseas&query&sort=rel×tamp=&viewType=list
주소를 보면 GET 방식으로 검색 카테고리, 페이지 번호, 검색 영역, 정렬 방식 등을 요청해서 페이지를 받아오는 방식이라는 걸 알 수 있습니다. 그렇다면 내가 원하는 검색 결과를 요청하는 주소를 만들어보면 다음과 같습니다.
https://search.shopping.naver.com/search/category?catId=50001395&frm=NVSHOVS&origQuery&pagingIndex=1&pagingSize=100&productSet=overseas&query&sort=rel×tamp=&viewType=list
저는 100개의 상품만 가져오면 되니까 "pagingSize"라는 파라미터만 기존 40에서 100으로 고치고 새로운 URL을 브라우저에서 열어보면 상품 100개가 한 번에 보이는 걸 확인할 수 있습니다. (이 글을 처음 쓸 때만 해도 100개까지 문제없이 가능했는데 며칠이 지난 지금은 80개가 최대네요.)
여기까지 왔다면 이제 절반은 한... 줄... 알았는데... 그게 아니었습니다. 이때까지만 해도 뭐 간단하네라고 생각했었습니다. ;;
아무튼 원하는 정보를 찾았으니 이제 파이썬에서 코딩을 시작해보겠습니다.
HTML 코드에서 상품명, 금액 등이 표시되는 태그를 찾을 수 있는 고유 이름을 찾아서 beautifulSoup으로 찾아줍니다.


각 항목의 클래스 속성에 고유 이름이 포함되어 있으니 그걸로 태그를 찾는데 이용합니다. 그리고 일단 찾는 내용들이 잘 크롤링되는지 확인하기 위해서 먼저 화면에 출력하도록 해봤습니다.
import requests
from bs4 import BeautifulSoup
import urllib
def main():
category = "50000151"
url = ("https://search.shopping.naver.com/search/category?frm=NVSHOVS&origQuery&"
"catId=" + category + "&" # category ID
"pagingIndex=1&" # 조회할 페이지번호
"pagingSize=" + "10&" # 페이지당 검색수
"productSet=overseas&" # 해외직구
"query&" # query: 검색 키워드
"sort=rel&" # sort=rel(네이버가격순)
"timestamp=&" #
"viewType=list") # viewType=list(리스트보기)
bs = BeautifulSoup(urllib.request.urlopen(url),"html.parser")
product_list = bs.select("li[class^='basicList_item']")
for li in product_list:
for goods in li.contents:
title = price = registerdate = 0
title = goods.select("a[class^='basicList_link__']")[0].text
price = goods.select("span[class^='price_num__']")[0].text
registerdate = goods.select("div[class^='basicList_etc_box__'] > span")[0].text
print(title, price, registerdate)
if __name__ == "__main__":
main()어?! 그런데 뭔가 이상한 게... 분명 한 페이지에 100개가 검색되도록 했는데 크롤링되는 건 5개밖에 없습니다. 몇 번을 해도 5개밖에 안 나와요.

네이버는 상품을 보여주는 페이지를 동적으로 구생해놓아서 처음에는 한 화면에 보일 정도의 상품만 로딩되었다가 스크롤을 내렸을 때 순서대로 추가 로딩이 되는 방식으로 구동합니다.
그렇기 때문에 한 페이지의 상품정보를 모두 가져오기 위해서는 페이지를 열고 마우스 스크롤을 화면 최 하단까지 내렸다가 그다음에 크롤링을 하는 과정을 거쳐야 합니다. 그리고 이런 방법을 위해서는 Selenium의 webdriver를 사용할 수 있겠죠.
Selelnium을 사용하면 쉽게 해결할 수 있는 문제이지만 크롤링에 시간이 오래 소요된다는 단점이 있습니다. 만약 여러 개의 카테고리에서 상품 목록을 추출하기 위해서 이런 동작을 반복해야 한다고 하면 1페이지 크롤링에 몇 초 정도만 걸려도 100번 반복하면 몇 분 정도의 시간이 걸리기 때문에 Selenium 사용은 피하고 싶습니다.
만약 상품 검색 페이지가 스크롤에 따라서 새로운 정보를 받아오는 거라면 개발자 도구를 이용해서 네트워크를 감시하면 뭔가 있지 않을까 해서 이리저리 뒤져봤지만 제품의 썸네일을 가져오는 거 말고는 새로운 정보를 요청하는 움직임은 찾지 못했고 특이한 건 제품 찜하기 정보는 페이지 전체에 해당하는 정보가 이미 들어와 있는 것을 확인했습니다.

그렇다면 어딘가에 제품 정보를 담고 있는 파일이 있다는 건데 도저히 찾지를 못하겠네요. 그런데 그러던 와중에 우연히 이런 정보를 발견했습니다.

json 포맷의 파일이며 요청한 상품 수량만큼의 모든 정보가 다 들어있습니다. 그런데 이상하게도 url로 최초 접속했을 때는 아무리 뒤져도 이 정보를 찾을 수 없는데 페이지가 한번 로딩되고 난 후 다음 페이지로 이동하거나 다른 카테고리로 이동하게 되면 이 정보를 확인할 수 있습니다.
이유는 모르지만 일단 이렇게 json파일이 확인이 되었으니 이제 크롤링의 방향을 바꾸기로 했습니다. json 정보만 받아와서 파싱 하면 더 간단히 해결되겠죠. 이럴 때 사용할 수 있는 아주 간단한 방법이 있는데요. 바로 cURL을 사용하는 방법입니다.
cURL은 Client URL을 의미한다고 하는데요. 원래 리눅스 커맨드 창에서 웹서버로부터 데이터를 받을 때 사용하는 웹 개발에 사용되는 툴이라고 합니다.
네트워크 응답에 마우스 오른쪽 클릭해서 "Copy > Copy as cURL"을 선택합니다. 이렇게 하면 해당 json파일을 서버에 요청하는 cURL 명령이 클립보드에 복사가 됩니다.

이렇게 복사된 cURL 명령을 다음 변환 사이트를 통해서 파이썬 명령으로 변환시켜줍니다.
Convert cURL command syntax to Python requests, Ansible URI, browser fetch, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSO
Language Ansible Browser (fetch) Dart Elixir Go Java JSON Node.js (fetch) Node.js (request) MATLAB PHP Python R Rust Strest
curl.trillworks.com
위 링크로 이동해서 좌측 curl command 창에 붙여 넣기를 하고 하단의 언어를 파이썬으로 골라주면 requests 모듈을 사용한 서버에 자료를 요청하는 스크립트로 자동으로 변환됩니다. 정말 신기하죠?!
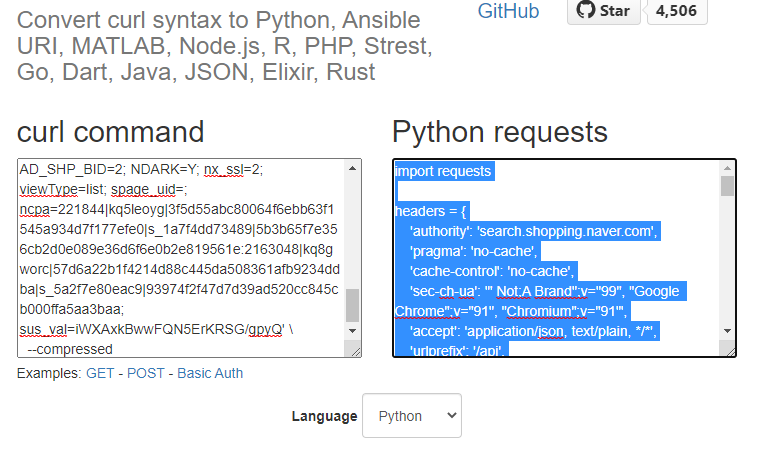
이렇게 만들어진 코드를 파이썬 IDE에 가져와서 필요한 수정을 하고 결과를 확인해 봅니다. 가져온 코드에서 추가한 부분은 2행, 40~49행입니다.
import requests
import json # 추가
headers = {
'authority': 'search.shopping.naver.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'accept': 'application/json, text/plain, */*',
'urlprefix': '/api',
'sec-ch-ua-mobile': '?0',
'logic': 'PART',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://search.shopping.naver.com/search/category?catId=50001395&frm=NVSHOVS&origQuery&pagingIndex=2&pagingSize=80&productSet=overseas&query&sort=rel×tamp=&viewType=list',
'accept-language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7,zh-CN;q=0.6,zh;q=0.5',
'cookie': 'NNB=NVV5OO7EOEVV4; NRTK=ag#all_gr#1_ma#-2_si#0_en#0_sp#0; _ga=GA1.2.1225184444.1584365530; ASID=27789460000001718f31904100000058; AD_SHP_BID=2; NDARK=Y; viewType=list; nx_ssl=2; _shopboxeventlog=false; sus_val=S3KSYAH/+vRxnJNcpDVS8eO3; spage_uid=',
}
params = (
('sort', 'rel'),
('pagingIndex', '1'),
('pagingSize', '80'),
('viewType', 'list'),
('productSet', 'overseas'),
('catId', '50001395'),
('deliveryFee', ''),
('deliveryTypeValue', ''),
('iq', ''),
('eq', ''),
('xq', ''),
('frm', 'NVSHOVS'),
('window', ''),
)
response = requests.get('https://search.shopping.naver.com/search/category', headers=headers, params=params)
# 여기서부터 추가코드-----------------------------
itemlist = json.loads(response.text)
itemlist['shoppingResult']['products']
for i in itemlist['shoppingResult']['products']:
title = i['productTitle']
price = i['price'],
registerdate = i['openDate'],
print(title, price, registerdate)json 파일을 파싱 해야 하기 때문에 json모듈을 추가했고 json파일을 itemlist라는 변수에 넣어서 json 계층구조에 맞게 원하는 정보를 찾아서 화면에 출력하도록 했습니다.
결과는 이렇게 짜란~~

배움은 끝이 없다는 걸 다시 한번 느끼게 되는 과정이었습니다.
끝!
'Software > Python' 카테고리의 다른 글
| Pyinstaller 패키징 때 PyQt ui 파일 포함시키는 방법(여러개도 됨) (0) | 2021.07.22 |
|---|---|
| pip upgrade 에러 - 엑세스가 거부, No module named 'pip' (0) | 2021.07.16 |
| Pyinstaller로 변환한 exe 파일의 실행 경로 찾기 (6) | 2021.07.08 |
| pyinstaller 에러 virtualenv로 해결하기 (Python 3.8.10 버전은 피하세요) (0) | 2021.07.06 |




댓글