아이패드 사용이 늘면서 종이책보다 전자책을 더 선호하게 되었습니다. 그래서 최근에 책을 살 일이 있으면 전자책이 있는지를 먼저 확인하고 가능하면 꼭 전자책을 구입하고 있습니다. 원래 취미에 독서가 없긴 하지만 그나마 전자책으로 가지고 있으면 언제든지 생각날 때마다 바로바로 꺼내 볼 수 있는 여건이 돼서 그나마 책을 좀 더 읽게 되는 것 같습니다.
하지만 아직 모든 출판물들이 전자책 출시를 하고 있지 않아 어쩔 수 없이 종이책을 살 수 밖에 없는 상황이 생기기도 합니다. 그리고 이미 가지고 있는 종이책도 많이 있기 때문에 이런 아쉬운 상황을 해결해 줄 북스캔에 대해서 좀 고민해 봤습니다. 종이책을 아이패드에 넣어 다니기 위해서 필요한 북스캔에 대한 내용 중 스캔 품질, 그중에서도 아크로뱃을 이용한 후처리 세팅에 대한 실험 결과 공유합니다.
테스트 배경
북스캔의 과정은 크게 스캐닝 과정과 후처리과정으로 나뉠 수 있는데, 그중에서도 품질에 가장 많은 영향을 미치는 것이 스캐닝일 것입니다. 아무리 후처리를 해서 보정을 한다고 해도 한계라는 게 있겠죠. 그래서 책을 스캔할 때 보통의 경우라면 300 DPI 화질로 진행하게 됩니다. 그 이하의 화질은 너무 구리고 300 DPI에 근접할수록 볼만한 수준이 된다고 일단 생각하시면 됩니다. 그리고 그 이상이 될수록 품질도 비례해서 좋아지긴 합니다만 체감하는 품질은 비례하지 않는 반면 투입되는 자원(작업시간, 저장공간)은 기하급수적으로 커지기 때문에 비효율적이죠. 따라서 무작정 높은 DPI로 스캔하는 건 낭비가 심하기 때문에 전문업체에서도 북스캔은 보통 300 DPI로 진행한다고 합니다.
그래서 전 "300DPI가 과연 최적인가?? 600 DPI로 스캔하더라도 후처리만 잘하면 용량은 유사하면서 품질은 뛰어난 결과를 만들어 낼 수 있지 않을까?? 그리고 후처리는 어떻게 해야 같은 품질에 용량을 최대로 줄일 수 있을지를 비교해 봤습니다.
스캔 품질 (300 DPI VS 600 DPI)
먼저 흑백의 한글로 된 출력물을 하나 준비를 하고 300 DPI로 한번 600 DPI로 한번 스캔을 해주었습니다.
후처리는 아크로벳 OCR (구 clearscan)
그리고 스캔된 파일을 각각 아크로벳 프로그램을 이용해서 스캔 및 OCR 도구로 텍스트 인식을 시켜주었습니다. 스캔된 문서를 아무런 처리 없이 이미지 그 자체로 소비할 수도 있겠지만 OCR 인식을 해두면 텍스트 검색 및 복사 등에 활용을 할 수도 있고 OCR 인식이 되면 문자 부분에 대해서는 이미지 정보가 아니라 폰트 정보로 변환되어 저장되기 때문에 용량이 줄어들고 가독성이 개선되는 효과가 있습니다.
제가 사용한 후처리 과정은 아크로벳의 "스캔 및 OCR"입니다.
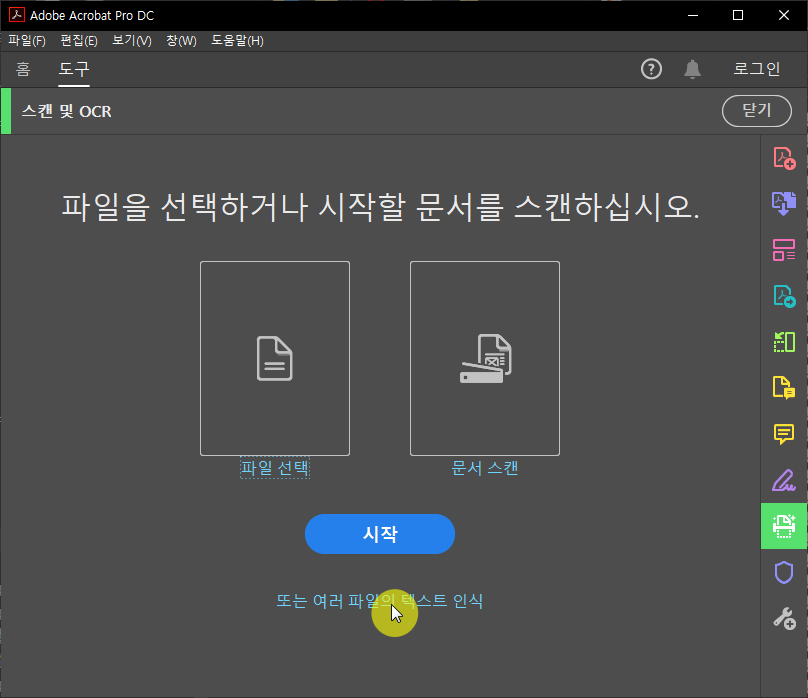
이때 한 가지 팁이라면 스캔파일을 모두 낱장으로 준비해서 여러 파일의 텍스트 인식으로 진행을 하는게 좋습니다. 그러니까 300페이지의 책을 스캔했다고하면 300개의 PDF파일로 분리를해서 여러 파일 텍스트 인식으로 처리를 하는 겁니다. 이유는 아크로벳 OCR이 불안정하기 때문입니다. 제 컴퓨터의 하드웨어 문제가 있어서인지는 모르겠지만 OCR을 진행하는 와중에 불특정 시점에서 프로그램이 다운되는일이 종종 발생했습니다. 그리고 다운이 되고나면 그전까지 진행되었던 OCR작업내용은 날아가 버리게되는데요. 제경우는 40페이지 이상의 파일을 한번에 성공한적은 한번도 없었습니다. (이정도로 심각한 상황은 모르긴 몰라도 일번적인 케이스는 아니겠죠?) 그래서 저처럼 낱장으로 진행을 하게되면 OCR결과물도 1장씩 변환이 끝나면 저장이 되기 때문에 중간에 다운이 되더라도 멈춘위치에서 다시 시작을 할 수 있습니다.
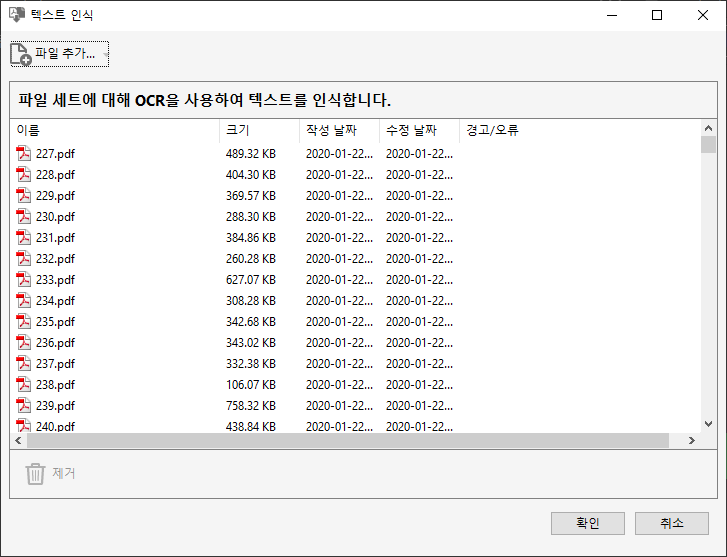
여러파일의 텍스트 인식을 선택하시면 이렇게 작업할 복수 파일을 선택해 줄 수 있습니다.
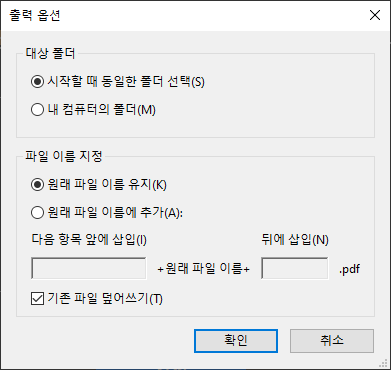
다음으로 결과물을 저장할 방법을 선택합니다.

마지막으로 OCR 처리 옵션을 선택해 줍니다. 출력 부분에 선택 가능한 옵션이 3가지가 있습니다. 검색할 수 있는 이미지로서 압축을 하는 옵션과 그렇지 않은 옵션이 있고 그리고 "편집 가능한 텍스트 및 이미지"라는 옵션이 있습니다.
여기서 어떤 옵션을 선택하는 게 가장 효율적인 것인지 감이 잘 안 오는데요. 그래서 제가 두 가지 옵션에 대해서 비교를 해 봤습니다.
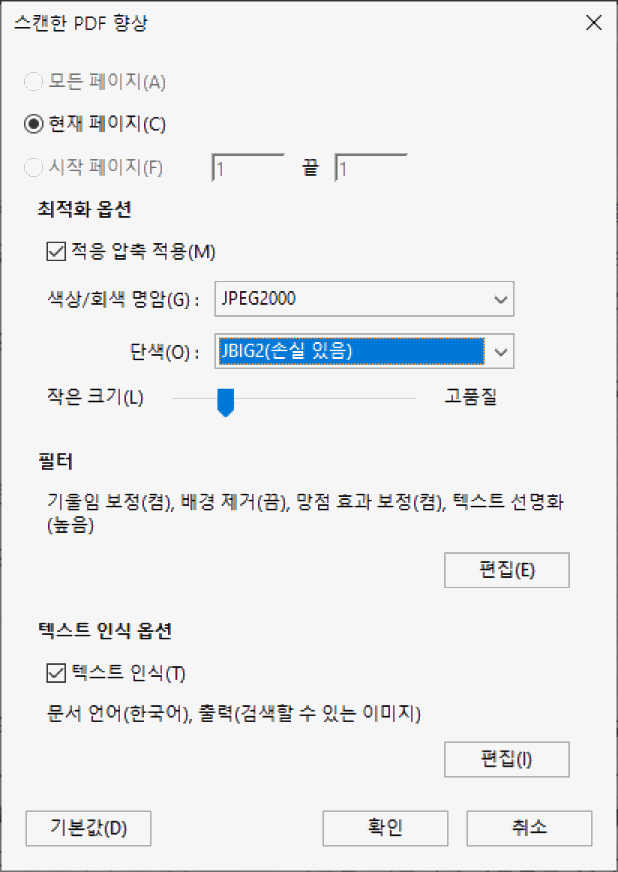
그리고 이렇게 아크로벳에서 OCR을 통한 후처리를 실행하기 위한 메뉴의 접근 경로는 한 가지만 있는 게 아닌데요. 아래 화면처럼 "스캔한 PDF 향상"이라는 메뉴로 접근을 하더라도 이 부분에 대한 옵션은 동일하게 선택 가능하기 때문에 동일한 기능이 적용된다는 것을 알 수 있습니다.
결과 비교
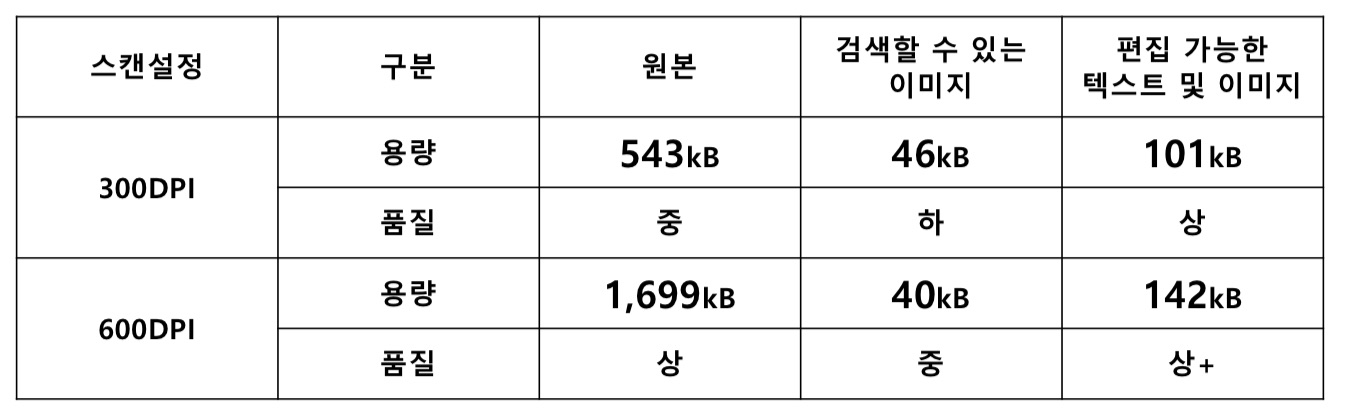
위 표는 결과를 비교해서 정리한 것인데요. 먼저 후처리를 위한 PDF 샘플은 앞서 설명한것처럼 300DPI와 600DPI 두가지로 준비를 하고 이것을 "검색할 수 있는 이미지"로 처리를 한것과 "편집 가능한 텍스트 및 이미지"로 처리를 한것 그리고 아무것도 하지 않은 원본의 3가지 결과물을 텍스트 품질과 용량에 대해서 비교를 한 것입니다.
스캔 품질의 경우 600DPI로 한 것이 300 DPI보다 당연히 깔끔하고 좋았습니다. 그런데 A4용지 1페이지 기준에서 스캔 결과물의 용량이 무려 3배가량 더 큰 결과를 보여주었습니다. 그리고 저는 북스캔용 전용 양면 스캐너를 사용하지 않았기 때문에 두 가지 설정값에 따라서 스캔에 걸리는 시간도 매우 큰 차이를 보여주었습니다. 시간을 측정해 보지는 않았지만 체감상 3배 이상 소요가 되는 듯 해 매우 비효율적이었습니다.
그리고 "검색할 수 있는 이미지"와 "편집 가능한 텍스트 및 이미지" 이 2가지 후처리 옵션에 대해서는 결과물의 장단이 극명하게 구분이 되어 결과물의 용도에 따라 상황에 맞는 선택을 할 수 있을 것 같았습니다.
"검색할 수 있는 이미지"의 경우 최대의 장점은 스캔한 파일의 용량이 대폭 줄어드는 효과가 있었습니다. 게다가 원본의 스캔 품질에 상관없이 결과물의 용량은 큰 차이가 없었습니다. 오히려 543kB 원본은 46kB가 된 반면 1,699kB의 더 큰 파일은 40kB로 되려 더 작은 결과가 나왔습니다. 하지만 단점은 용량에서 큰 이득을 보는 대신에 품질에서는 약간 손해가 있습니다. 후처리 결과물은 원본보다도 화질이 떨어지는 결과를 보여주었기 때문에 "검색할 수 있는 이미지" 옵션은 약간의 화질 손해를 감수하더라도 최고 효율의 용량압축이 필요할 때 유용할 것 같습니다.
마지막으로 "편집 가능한 텍스트 및 이미지" 옵션은 제가 생각했을 때는 나름 최적화 옵션인 것 같습니다. 용량은 "검색할 수 있는 이미지" 옵션만큼 파격적이진 않지만 그래도 80~90%가량의 파일크기 축소가 능했으며 텍스트에 대한 스캔 품질은 오히려 더 개선되는 효과를 가져왔습니다. 품질의 경우 주관적인 요소이며 가독성 면에서 가장 자연스러운 건 후처리를 하지 않은 원본이긴 합니다. 하지만 스캔한 자료를 보통의 PC 화면에서가 아니라 모바일 화면에서 본다고 하면 경우에 따라 확대해서 볼 일도 생기는데 그런 경우 이 "편집 가능한 텍스트 및 이미지" 옵션으로 후처리를 하면 텍스트가 더 선명해지기 때문에 유리한 면이 있습니다.
품질에 대한 결과는 아래를 보시고 직접 판단해 보세요.
300 DPI 결과
300 DPI로 스캔을 하고 후처리를 하여 비교한 결과입니다.

후처리를 하고 나면 글씨의 윤곽이 더 분명해지면서 선명 해졌다는 건 느낄 수 있죠. 이렇게만 보면 "검색할 수 있는 이미지" 옵션도 나쁘지 않습니다.
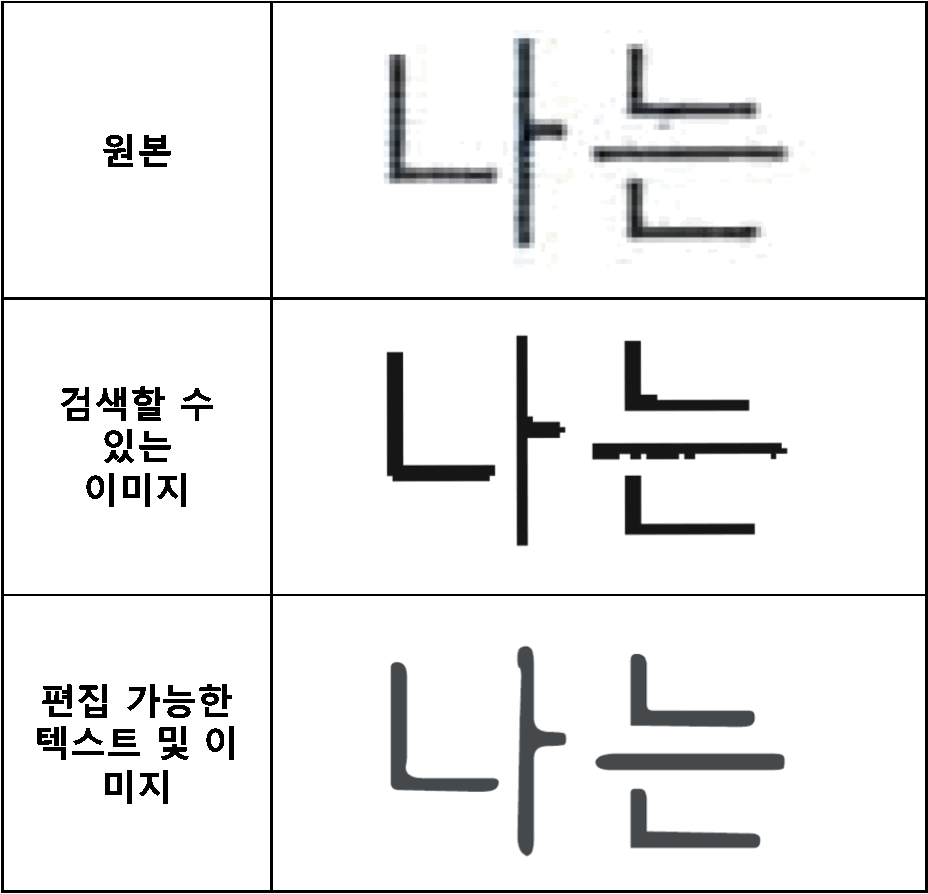
글씨를 확대해보면 각 옵션별로 차이를 확연히 볼 수 있는데요. 원본 이미지는 글씨의 경계가 분명하지 못하고 색이 번진 것 같이 보이는데요. 확대를 할수록 더 지저분해 보입니다. 하지만 후처리를 하고 나면 이 경계가 명확해집니다. 그리고 마치 벡터 이미지처럼 아무리 확대를 해도 깨끗한 이미지를 볼 수 있습니다. 그래서 이미지의 깔끔함 면에서는 "편집 가능한 텍스트 및 이미지" 옵션이 훨씬 깔끔합니다.
600 DPI 결과

600 DPI로 스캔하면 일단 원본 이미지 품질이 매우 만족스럽습니다. 그래서 후처리 결과도 300 DPI에서보다 좀 더 깨끗해 보이는 것 같죠?!

그리고 확대를 하면 앞에서와 마찬가지로 "편집 가능한 텍스트 및 이미지" 옵션이 가장 최적의 옵션으로 보입니다. 하지만 600 DPI의 원본을 사용했다고 후처리 품질이 특별히 더 나아 보이지는 않습니다. "검색할 수 있는 이미지" 옵션은 개선이 되는 것 같지만 "편집 가능한 텍스트 및 이미지"에서는 큰 차이를 찾기가 어렵죠.
결론
북스캔을 할 때 어떤 방법이 가장 효과적일지를 비교를 해 봤는데요. 제 결론은 'OCR 후처리는 일단 파일크기, 가독성, 스캔물 활용면에서 매우 유용한 기능이기 때문에 가능하면 꼭 사용하는 게 좋으며 그 방법으로는 아크로벳의 "편집 가능한 텍스트 및 이미지"옵션을 사용해 OCR처리를 하는게 가장 효과적이다'입니다. 그리고 스캔 시 화질은 굳이 600 DPI로 시간과 용량을 많이 소요시켜서 해봐야 후처리를 하게 되면 300 DPI로 한 것과 큰 차이가 없기 때문에 300 DPI가 최적의 선택이라는 결론에 도달했습니다. (이미지가 많은 출력물이라면 얘기가 달라질 수 있겠지만요.)
끝!
'Tips' 카테고리의 다른 글
| 아이패드 마우스 스크롤 방향 변경하기 (8) | 2020.04.07 |
|---|---|
| 블루투스5? 블루투스의 버전, 규격, 프로파일 그리고 오디오 코덱 (7) | 2020.03.26 |
| 우리은행 외화예금통장 개설 그리고 애드센스 수익금 지급계좌 등록 (6) | 2019.10.30 |
| 윈도우 자동로그인 레지스트리 (2) | 2019.10.29 |



댓글